OP.NUB.1 Servicios en la nube
OP.NUB.1 Protección de servicios en la nube
Documentos de referencia
-
ENS (Esquema Nacional de Seguridad):
- Real Decreto 311/2022 - Requisitos de seguridad para servicios cloud
- CCN-STIC 823 - Utilización de servicios en la nube
- CCN-STIC 884 - Guía de configuración segura para AWS
- CCN-STIC 885 - Guía de configuración segura para Azure
-
Normativa Internacional:
- ISO/IEC 27017:2015 - Code of practice for cloud services
- ISO/IEC 27018:2019 - Protection of PII in public clouds
- NIST SP 800-53 rev5 - Security and Privacy Controls
- CSA Cloud Controls Matrix v4.0
-
Regulación Sector Salud:
- EU MDR 2017/745 - Medical Device Regulation
- FDA Guidance - Cybersecurity in Medical Devices (2023)
- NIS2 Directive - Critical infrastructure protection
- HIPAA/HITECH - Healthcare data protection
-
AWS Specific Compliance:
- AWS Well-Architected Framework - Security Pillar
- AWS Security Best Practices
- AWS Shared Responsibility Model
- AWS Compliance Programs (SOC 2, ISO 27001, HIPAA)
Guía de implantación
- La protección de servicios en la nube para sistemas de categoría ALTA en las cinco dimensiones de seguridad requiere:
- Modelo de responsabilidad compartida claramente definido
- Controles de seguridad específicos para entorno cloud
- Gestión de identidades y accesos robusta
- Cifrado de datos en tránsito y reposo
- Monitorización y auditoría continua
- Gestión de incidentes coordinada con el proveedor
- Cumplimiento regulatorio verificado
Implementación en la plataforma
Arquitectura Cloud de la plataforma
Visión General de la Infraestructura AWS
La plataforma opera como un dispositivo médico SaaS Clase IIa desplegado completamente en AWS, con la siguiente arquitectura:
Infraestructura AWS de la plataforma:
Regiones:
- Primaria: eu-west-1 (Irlanda)
- DR/Backup: eu-central-1 (Frankfurt)
Estructura de Cuentas:
| Cuenta | Criticidad | Propósito | Cumplimiento |
|---|---|---|---|
| Production | Crítica | Sistema productivo | HIPAA, GDPR, MDR, ENS |
| Staging | Alta | Validación pre-producción | GDPR, ENS |
| Development | Media | Desarrollo y pruebas | Interno |
Arquitectura de Red (VPCs):
| Entorno | Rango CIDR | Segmentación |
|---|---|---|
| Production | 10.0.0.0/16 | • Public subnets: Load balancers, NAT gateways • Private subnets: Application servers, databases • Isolated subnets: Critical data processing |
| Staging | 10.1.0.0/16 | Similar segmentation |
| Development | 10.2.0.0/16 | Similar segmentation |
1.2 Servicios AWS Críticos Utilizados
| Servicio AWS | Función | Criticidad | Controles ENS Aplicados |
|---|---|---|---|
| ECS Fargate | Contenedores de aplicación | CRÍTICA | mp.sw.1, op.exp.2 |
| RDS PostgreSQL | Base de datos clínica | CRÍTICA | mp.info.3, op.exp.11 |
| S3 | Almacenamiento de imágenes médicas | CRÍTICA | mp.info.4, mp.si.2 |
| CloudFront | CDN y protección DDoS | ALTA | mp.com.1, op.mon.1 |
| API Gateway | Autenticación y control de acceso a la API | CRÍTICA | op.acc.1, op.acc.5 |
| KMS | Gestión de claves de cifrado | CRÍTICA | mp.cryp.1, op.exp.11 |
| CloudWatch | Monitorización y logs | ALTA | op.mon.2, op.exp.8 |
| Lambda | Procesamiento serverless | MEDIA | op.exp.2, mp.sw.2 |
| API Gateway | Gestión de APIs | ALTA | mp.com.2, op.acc.7 |
| Secrets Manager | Gestión de secretos | CRÍTICA | mp.cryp.2, op.exp.11 |
Modelo de Responsabilidad Compartida
Matriz de Responsabilidades AWS vs la organización
Matriz de Responsabilidad Compartida:
| Área | Responsable | Responsabilidades |
|---|---|---|
| Infraestructura Física | AWS | • Seguridad física de datacenters • Mantenimiento de hardware y red • Seguridad del hipervisor • Disponibilidad de infraestructura global |
| Servicios Gestionados | AWS | • Patching y backups de RDS • Durabilidad y disponibilidad de S3 • Infraestructura de gestión de claves KMS • Ubicaciones edge de CloudFront |
| Protección de Datos | La organización | • Clasificación y manejo de datos • Gestión de claves de cifrado • Políticas de control de acceso • Retención y eliminación de datos |
| Seguridad de Aplicación | La organización | • Seguridad del código de aplicación • Seguridad de imágenes de contenedores • Seguridad de APIs • Gestión de identidades y accesos |
| Cumplimiento Regulatorio | La organización | • Regulaciones de dispositivos médicos (MDR, FDA) • Privacidad de datos (GDPR, HIPAA) • Estándares de seguridad (ENS, ISO 27001) • Auditoría y monitorización |
Controles Específicos por Capa
| Capa | Responsable | Controles Implementados |
|---|---|---|
| Datos | La organización | Cifrado AES-256, clasificación, DLP |
| Aplicación | La organización | SAST, DAST, dependency scanning |
| Sistema Operativo | Compartido | Hardening, patching automático |
| Red | Compartido | Security groups, NACLs, WAF |
| Virtualización | AWS | Aislamiento, hypervisor security |
| Hardware | AWS | HSM, secure disposal, physical security |
| Instalaciones | AWS | Biometrics, CCTV, 24/7 security |
Gestión de Identidades y Accesos Cloud (IAM)
Estrategia IAM Multinivel
Estrategia IAM Multinivel:
El equipo de seguridad debe implementar una estrategia de gestión de identidades con múltiples proveedores:
Proveedores de Identidad:
- API: API keys + OAuth 2.0 client credentials — para la autenticación máquina-a-máquina de los sistemas clientes que consumen la API. Los profesionales sanitarios y pacientes no interactúan directamente con nuestro sistema; acceden a través de las aplicaciones de sus organizaciones, que se integran con nuestra API
- Administrativo: AWS IAM + Google Workspace — para el personal interno de la organización
Límites de Permisos por Entorno:
- Production: Política de límite estricta para prevenir escalada de privilegios
- Staging: Política de límite moderada para validación
- Development: Política de límite permisiva para desarrollo
Implementación del Principio de Menor Privilegio:
Para cada rol, el sistema debe:
- Crear política IAM con versión 2012-10-17
- Para cada permiso necesario:
- Especificar acciones permitidas
- Definir recursos específicos (no usar comodines cuando sea posible)
- Añadir condiciones de seguridad obligatorias
- Condiciones de seguridad obligatorias:
- IpAddress: Solo permitir desde VPC (10.0.0.0/8)
- SecureTransport: Requerir HTTPS siempre
- Tags de Principal: Verificar Environment y DataClassification
La implementación técnica debe mantenerse en la documentación de infraestructura.
Roles y Políticas Críticas
| Rol | Permisos | Condiciones | MFA Requerido |
|---|---|---|---|
| MedicalDataProcessor | S3:GetObject (medical images) | IP whitelist, time window | Sí |
| ClinicalAdmin | RDS:DescribeDBInstances | VPC only, tagged resources | Sí |
| SecurityAuditor | Read-only all services | CloudTrail enabled | Sí |
| IncidentResponder | Full access (emergency) | Break-glass procedure | Sí |
| DataScientist | SageMaker, S3 (anonymized) | Dev environment only | Sí |
Cifrado y Protección de Datos
Estrategia de Cifrado Multicapa
Estrategia de Cifrado Multicapa:
Cifrado de Datos en Reposo:
| Tipo de Dato | Algoritmo | Gestión de Claves | Rotación | Políticas Especiales |
|---|---|---|---|---|
| Imágenes Médicas en S3 | AES-256 | AWS KMS CMK | Anual | Denegar uploads sin cifrar |
| Datos Clínicos en RDS | AES-256 | AWS KMS CMK | Anual | Backups cifrados habilitados |
| Volúmenes EBS | AES-256 | AWS KMS | Según política | Cifrado por defecto en toda la cuenta |
Cifrado de Datos en Tránsito:
| Comunicación | Protocolo | Detalles | Gestión de Certificados |
|---|---|---|---|
| APIs Externas | TLS 1.3 | Cipher suite: ECDHE-RSA-AES256-GCM-SHA384 HSTS habilitado (max-age=31536000) | AWS Certificate Manager |
| Comunicaciones Internas VPC | AWS PrivateLink | Service mesh: AWS App Mesh con mTLS | Automática |
| Conexiones a Base de Datos | SSL/TLS | SSL/TLS requerido obligatoriamente | RDS managed |
Gestión de Claves:
| Tipo de Clave | Características | Auditoría |
|---|---|---|
| Master Keys (CMK) | Customer Managed, rotación automática anual, replicadas a región DR | CloudTrail en todas las operaciones |
| Data Keys | Generadas on-demand desde CMK, caché máximo 5 minutos | CloudTrail en todas las operaciones |
Data Loss Prevention (DLP)
Controles de Data Loss Prevention (DLP) en Cloud:
El sistema debe implementar controles automáticos de DLP para prevenir fugas de datos sensibles:
Patrones de Datos Sensibles a Detectar:
- DNI español (9 dígitos)
- Tarjetas de crédito (16 dígitos)
- Números NHS (formato británico)
- SSN estadounidense (formato XXX-XX-XXXX)
Niveles de Clasificación:
| Nivel | Nombre | Valor | Tratamiento |
|---|---|---|---|
| 0 | Public | Público | Sin restricciones especiales |
| 1 | Internal | Interno | Acceso solo empleados |
| 2 | Confidential | Confidencial | Acceso restringido |
| 3 | Medical | Médico | Cifrado adicional obligatorio |
| 4 | Critical | Crítico | Máxima protección |
Escaneo de Contenido en S3:
Antes de subir cualquier archivo a S3, el sistema debe:
- Clasificar el contenido automáticamente
- Si es nivel médico o superior:
- Aplicar cifrado adicional con KMS
- Registrar en auditoría
- Si contiene datos sensibles:
- Bloquear la subida O
- Redactar/enmascarar la información sensible
Políticas de Bucket:
Todos los buckets deben tener política que:
- Deniegue uploads sin cifrado
- Requiera cifrado KMS (aws:kms)
- Aplique a todos los objetos (*)
Seguridad de Red y Perímetro
Arquitectura de Seguridad en Profundidad
Arquitectura de Seguridad en Profundidad:
Capa 1 - Protección Edge:
| Servicio | Controles |
|---|---|
| CloudFront | • AWS Shield Standard (protección DDoS) • AWS WAF (firewall de aplicación) • Origin Access Identity (protección S3) • Geo-restriction (solo UE) |
| Route53 | • DNSSEC habilitado • Protección DDoS • Health checks con failover automático |
Capa 2 - Seguridad de Perímetro:
| Componente | Configuración |
|---|---|
| Internet Gateway | • Security groups restrictivos • Network ACLs (reglas stateless) • Flow logs habilitados |
| NAT Gateway | • Solo tráfico saliente para subnets privadas • Elastic IPs fijas • Monitorización CloudWatch |
Capa 3 - Segmentación Interna:
Security Groups - Ejemplo de aplicación médica:
- Inbound:
- Puerto 443 desde ALB security group
- Puerto 5432 (PostgreSQL) desde app security group
- Outbound:
- Puerto 443 hacia Internet (actualizaciones, APIs externas)
Network ACLs - Subnet privada:
| Regla | Protocolo | Puerto | Origen | Acción |
|---|---|---|---|---|
| 100 | TCP | 443 | 10.0.0.0/16 (VPC) | ALLOW |
| 200 | TCP | 5432 | 10.0.1.0/24 (subnet app) | ALLOW |
| 32767 | ALL | ALL | 0.0.0.0/0 | DENY (default) |
AWS WAF implementado
El Web Application Firewall (WAF) está implementado y operativo en producción, integrado con el Application Load Balancer (ALB) del backend.
Configuración General:
- Nombre del Web ACL:
app-pro-backend-waf - Ámbito: Regional (integrado con ALB)
- Región: eu-west-3
- Acción por defecto: ALLOW (las reglas gestionadas bloquean tráfico malicioso)
Reglas Implementadas (4 reglas activas):
| Prioridad | Nombre | Tipo | Propósito | Acción |
|---|---|---|---|---|
| 1 | AWS-AWSManagedRulesAmazonIpReputationList | AWS Managed Rule | Bloquear IPs con mala reputación conocida (botnets, proxies) | BLOCK |
| 2 | AWS-AWSManagedRulesKnownBadInputsRuleSet | AWS Managed Rule | Proteger contra entradas maliciosas conocidas (SQLi, XSS, etc.) | BLOCK |
| 3 | protect-anonymized-diagnostic-reports | Custom Rule | Protección específica para las APIs de informes diagnósticos | BLOCK |
| 4 | Default Action | — | Permitir tráfico legítimo que pasa todas las reglas | ALLOW |
Evidencia de funcionamiento:
El dashboard de AWS WAF muestra que el firewall está filtrando tráfico activamente:
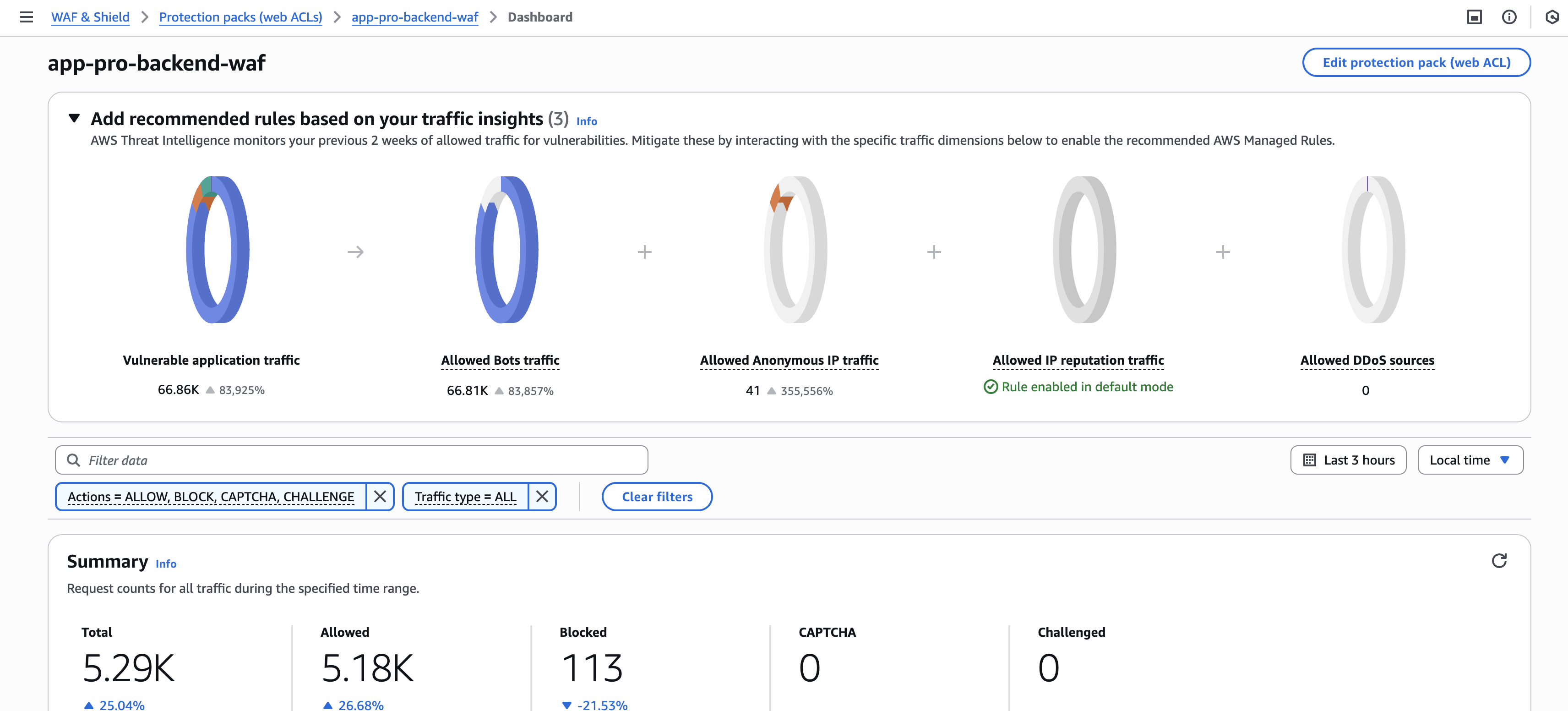
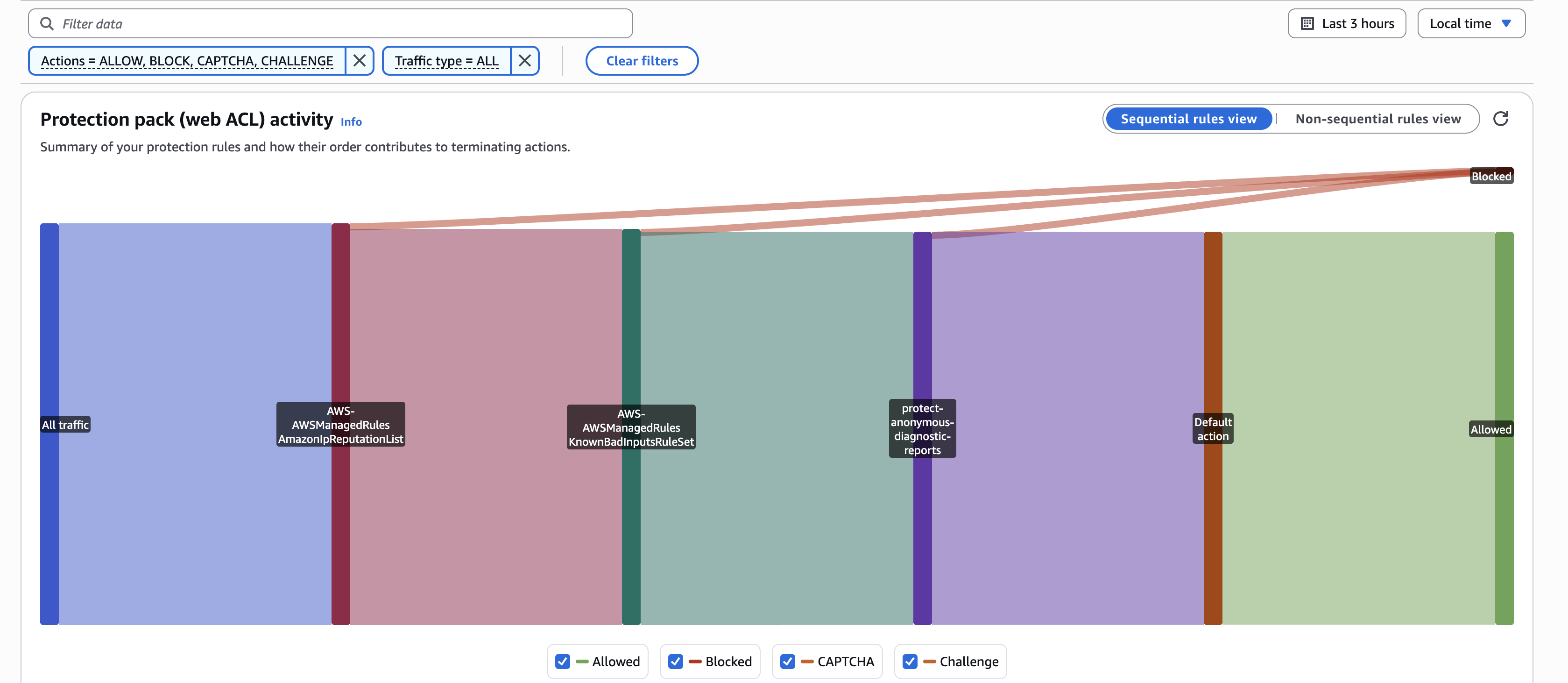
Estas reglas proporcionan defensa en profundidad específica para un dispositivo médico SaaS, combinando reglas gestionadas por AWS (inteligencia de amenazas actualizada automáticamente) con reglas personalizadas para la protección de las APIs del dispositivo.
Monitorización y Auditoría Cloud
Stack de Observabilidad Cloud-Native
Stack de Observabilidad Cloud-Native:
CloudTrail - Auditoría de API:
- Configuración:
- Trail multi-región habilitado
- Validación de archivos de log habilitada
- Registrar todos los eventos de lectura y escritura
- Eventos de gestión incluidos
- Recursos de datos monitorizados: Objetos S3 de imágenes médicas, clusters RDS
- Integración:
- Logs enviados a CloudWatch Logs
- Almacenamiento en S3: bucket "audit-trail-medical-device"
- Notificaciones SNS habilitadas
- Cifrado con KMS CMK
CloudWatch - Métricas y Logs:
| Componente | Configuración | Detalles |
|---|---|---|
| Métricas Personalizadas | Namespaces: Medical, Security, Compliance | Métricas críticas: API latency p99, error rate, authentication failures, data access anomalies |
| Log Groups | /aws/ecs/medical-app /aws/rds/clinical-db /aws/lambda/image-processor | Retención: 2555 días (7 años requisito médico) Cifrado: KMS CMK |
| Alarmas Alta Prioridad | Unauthorized API calls Root account usage Config changes Security group changes | Notificación inmediata al equipo de seguridad |
AWS Config - Cumplimiento Continuo:
- Reglas Habilitadas:
- s3-bucket-public-read-prohibited
- rds-encryption-enabled
- iam-password-policy
- mfa-enabled-for-iam-console-access
- cloudtrail-enabled
- Remediación: Automática habilitada con notificación al equipo de seguridad
Security Information and Event Management (SIEM)
Integración SIEM en Cloud:
El equipo de seguridad debe implementar un SIEM que integre las siguientes fuentes de eventos:
- CloudTrail (auditoría de APIs)
- VPC Flow Logs (tráfico de red)
- CloudWatch Logs (aplicaciones)
- GuardDuty (detección de amenazas)
- Security Hub (hallazgos de seguridad)
- Access Analyzer (análisis de accesos)
Procesamiento de Eventos de Seguridad:
- Enriquecimiento: Añadir contexto adicional al evento (usuario, ubicación, historial)
- Cálculo de riesgo: Asignar puntuación de riesgo 0-100
- Respuesta automática según riesgo:
- >80 (Crítico): Activar respuesta a incidentes automática
- 60-80 (Alto): Crear alerta de seguridad
- <60: Almacenar para análisis
- Almacenamiento: Guardar todos los eventos para análisis forense posterior
Detección de Anomalías:
El sistema debe analizar ventanas temporales (ej: última hora) para detectar:
- Patrones de acceso inusuales: Desviación >3 sigmas = alerta de severidad alta
- Picos en uso de recursos: Detección de spikes anómalos = alerta de severidad media
Los detalles técnicos de implementación deben mantenerse en la documentación del SIEM.
Gestión de Incidentes Cloud
Procedimiento de Respuesta a Incidentes AWS
Procedimiento de Respuesta a Incidentes AWS:
1. Detección:
- Fuentes Automatizadas:
- Hallazgos de GuardDuty
- Alertas de Security Hub
- Alarmas de CloudWatch
- Detecciones personalizadas Lambda
- Fuentes Manuales:
- Reportes de usuarios
- Revisiones de seguridad
- Pruebas de penetración
2. Triaje:
| Severidad | Indicadores | Tiempo de Respuesta | Ejemplos |
|---|---|---|---|
| Crítico | < 15 minutos | Respuesta inmediata | • Data breach detectado • Indicadores de ransomware • Compromiso de credenciales admin |
| Alto | < 1 hora | Respuesta prioritaria | • Actividad API sospechosa • Acceso inusual a datos • Picos de autenticación fallida |
| Medio | < 4 horas | Respuesta programada | • Configuration drift • Violaciones de políticas • Uso indebido de recursos |
3. Contención:
- Acciones Automatizadas:
- Aislar instancias comprometidas
- Revocar credenciales sospechosas
- Bloquear IPs maliciosas
- Crear snapshots de recursos afectados
- Acciones Manuales:
- Revisar logs de CloudTrail
- Analizar VPC Flow Logs
- Crear imágenes forenses
- Notificar al equipo legal
4. Erradicación:
- Eliminar artefactos maliciosos
- Parchear vulnerabilidades
- Resetear credenciales comprometidas
- Actualizar security groups
5. Recuperación:
- Validación:
- Verificar integridad del sistema
- Escaneo de seguridad
- Pruebas de funcionalidad
- Validación de rendimiento
- Restauración:
- Restauración gradual de servicios
- Monitorizar recurrencia
- Comunicación a usuarios
6. Lecciones Aprendidas:
- Documentar línea temporal del incidente
- Análisis de causa raíz
- Efectividad de la respuesta
- Recomendaciones de mejora
Automatización de Respuesta con Lambda
Automatización de Respuesta con Lambda:
El equipo técnico debe implementar funciones Lambda para respuesta automática a incidentes con los siguientes componentes:
Clientes AWS necesarios:
- EC2 (gestión de instancias)
- IAM (gestión de credenciales)
- SNS (notificaciones)
- S3 (almacenamiento de evidencias)
Handler Principal:
La función Lambda debe:
-
Identificar tipo de incidente del evento recibido
-
Mapear acción de respuesta:
- Llamada API no autorizada → Manejar API no autorizada
- Instancia sospechosa → Aislar instancia
- Compromiso de credenciales → Revocar credenciales
- Exfiltración de datos → Bloquear transferencia
-
Ejecutar respuesta automática si el tipo es reconocido
-
Notificar al equipo de seguridad
-
Crear snapshot forense
-
Retornar resultado con ID del incidente, acciones tomadas y timestamp
Ejemplo: Aislamiento de Instancia Comprometida:
Cuando se detecta una instancia comprometida:
- Crear security group de aislamiento específico para esta instancia
- Aplicar security group restrictivo que bloquea todo el tráfico
- Crear snapshot de la instancia para análisis forense posterior
- Documentar acción: Registrar ID de instancia, ID de security group de aislamiento
Esta automatización permite respuesta en segundos, minimizando el impacto de incidentes.
Continuidad de Negocio y Disaster Recovery
Estrategia Multi-Región
Estrategia de Disaster Recovery Multi-Región:
Arquitectura:
- Región Primaria: eu-west-1 (Irlanda)
- Región DR: eu-central-1 (Frankfurt)
Replicación por Componente:
| Componente | Tipo de Replicación | RPO | RTO |
|---|---|---|---|
| Base de Datos | RDS Cross-Region Read Replica | 5 minutos | 30 minutos |
| Almacenamiento | S3 Cross-Region Replication | 15 minutos | 5 minutos |
| Aplicación | ECS Blue-Green Deployment | 0 minutos | 15 minutos |
Estrategia de Backups:
| Recurso | Frecuencia | Retención | Detalles |
|---|---|---|---|
| RDS | Diario | 35 días | Ventana: 03:00-04:00 UTC |
| S3 | Continuo (versionado) | 90 días → Glacier | MFA Delete habilitado |
| Secretos | Rotación cada 90 días | Últimas 5 versiones | Versionado automático |
Testing y Validación:
| Tipo de Test | Frecuencia | Alcance | Duración/Validación |
|---|---|---|---|
| DR Drills | Trimestral | Full failover test | 4 horas |
| Restauración de Backups | Mensual | Muestra aleatoria | Check de integridad de datos |
Automatización de Failover
Automatización de Failover a Región DR:
El equipo técnico debe implementar automatización de failover que utilice:
- Route53 (gestión DNS)
- RDS (gestión de bases de datos)
- ECS (gestión de contenedores)
Proceso de Failover Automatizado:
Cuando se inicia un failover (con razón documentada y autorización):
-
Documentar inicio:
- Timestamp
- Razón del failover
- Persona que autoriza
- Pasos ejecutados
-
Promover Read Replica a Primary:
- La réplica de lectura en región DR se promociona a base de datos primaria
- Registrar resultado de la promoción
-
Actualizar registros DNS:
- Route53 actualiza registros para apuntar a región DR
- Registrar cambios DNS realizados
-
Escalar servicios en DR:
- Aumentar capacidad de servicios ECS en región DR
- Registrar escalado realizado
-
Verificar health checks:
- Confirmar que todos los servicios pasan health checks
- Registrar estado de salud
-
Notificar a stakeholders:
- Informar a equipo técnico y management
- Incluir plan completo de failover ejecutado
Este proceso automatizado reduce el RTO a minutos en lugar de horas.
Compliance y Auditoría Cloud
Controles de Cumplimiento Automatizados
Reglas de AWS Config para Dispositivos Médicos:
| Regla | Descripción | Remediación Automática |
|---|---|---|
| medical-s3-encryption-required | Todos los datos médicos deben estar cifrados | Cifrado automático con KMS |
| medical-rds-backup-enabled | Backups de bases de datos obligatorios | Activación de backups automáticos |
| medical-cloudtrail-enabled | Registro de auditoría obligatorio | Activación de CloudTrail con validación |
| medical-mfa-required | MFA para todos los usuarios privilegiados | Bloqueo de acceso hasta activar MFA |
Estándares de Security Hub:
- AWS Foundational Security Best Practices
- CIS AWS Foundations Benchmark
- PCI DSS
- HIPAA
Controles Personalizados:
| Control | Título | Descripción | Severidad |
|---|---|---|---|
| MED-001 | Medical Image Encryption | Verificar que todas las imágenes médicas están cifradas | CRÍTICA |
| MED-002 | Clinical Data Access Logging | Todo acceso a datos clínicos debe registrarse | ALTA |
Informes Automatizados:
| Informe | Frecuencia | Formato | Destinatarios | Retención |
|---|---|---|---|---|
| ENS Compliance Report | Mensual | PDF + JSON | Compliance y Responsable de Seguridad | - |
| Medical Device Audit | Trimestral | Escaneo completo | Auditoría | 7 años |
Evidencia de Cumplimiento
El sistema de recolección de evidencia automatizada genera informes de cumplimiento ENS que incluyen:
Información del Sistema:
- Fecha del informe
- Nombre del dispositivo
- Categoría ENS: ALTA
- Dimensiones de seguridad:
- Confidencialidad: ALTA
- Integridad: ALTA
- Disponibilidad: ALTA
- Autenticidad: ALTA
- Trazabilidad: ALTA
Proceso de Generación:
- Obtener mapeo de controles ENS - El sistema consulta la correspondencia entre controles ENS y reglas de AWS Config
- Verificar cumplimiento por control - Para cada control ENS, se verifica el estado de las reglas AWS Config asociadas, recopilando:
- Estado de cumplimiento
- Evidencia técnica
- Fecha de última evaluación
- Añadir hallazgos de Security Hub - Se incluyen los findings activos de Security Hub relevantes
- Calcular score de cumplimiento - Se genera una puntuación agregada basada en el estado de todos los controles
- Generar informe - El informe final se emite en formato PDF y JSON para distribución automática
Gestión de Costes y Optimización
FinOps para Dispositivo Médico
Presupuestos Mensuales:
| Entorno | Límite Mensual | Alertas |
|---|---|---|
| Production | 50.000 € | 50%, 80%, 100%, 120% |
| Development | 10.000 € | 80%, 100% |
| Compliance Reserve | 100.000 €/año | Auditorías, certificaciones, remediación |
Estrategias de Optimización:
| Estrategia | Objetivo/Configuración | Término | Notas |
|---|---|---|---|
| Reserved Instances | Cobertura 80% | 1 año | Pago parcial adelantado |
| Savings Plans | Compromiso 30.000 €/mes | 1 año | Compute commitment |
| Spot Instances | Batch processing, development, testing | - | Terminación ante interrupción |
Gestión del Ciclo de Vida de Datos (S3):
| Período | Nivel de Almacenamiento | Tipo de Datos |
|---|---|---|
| 0-30 días | S3 Standard | Imágenes médicas activas |
| 31-90 días | S3 Infrequent Access | Imágenes recientes |
| 91-365 días | S3 Glacier | Archivo histórico |
| 365+ días | Glacier Deep Archive | Retención regulatoria |
Etiquetas de Asignación de Costes:
- Environment: Production, Staging, Development
- Department: Engineering, Clinical, Compliance
- Project: AI-Model, Infrastructure, Security
- Compliance: ENS, MDR, HIPAA
Integración con Servicios de Seguridad AWS
AWS GuardDuty para Detección de Amenazas
Configuración de Detección:
- Estado: Habilitado
- Frecuencia de publicación: 15 minutos
Tipos de Detectores Activos:
- Reconocimiento de instancias
- Comunicación con IPs maliciosas
- Minería de criptomonedas
- Acceso a credenciales
- Exfiltración de datos
Fuentes de Inteligencia de Amenazas:
- Feeds gestionados por AWS
- IoCs personalizados para dispositivos médicos
- Inteligencia de amenazas del sector sanitario
Reglas de Supresión:
| Regla | Filtro | Propósito |
|---|---|---|
| Known vulnerability scanners | Organización = 'Security Vendor' | Excluir escáneres de seguridad autorizados |
| Authorized penetration testing | Tag 'PenTest' = 'Authorized' | Excluir pruebas de penetración autorizadas |
Automatización de Respuesta por Severidad:
| Severidad | Acciones Automáticas |
|---|---|
| ALTA | • Crear finding en Security Hub • Activar función Lambda de respuesta • Enviar a SIEM • Notificar al equipo de seguridad de guardia |
| MEDIA | • Crear finding en Security Hub • Enviar a SIEM • Email al equipo de seguridad |
| BAJA | • Registrar en CloudWatch • Informe semanal resumido |
AWS Security Hub Centralizado
El equipo de seguridad configura Security Hub con estándares específicos para dispositivos médicos:
Estándares Habilitados:
| Estándar | Versión | Controles Deshabilitados | Notas |
|---|---|---|---|
| AWS Foundational Security Best Practices | v1.0.0 | Ninguno | Todos los controles habilitados |
| CIS AWS Foundations Benchmark | v1.4.0 | CIS.2.8 | Excepción documentada |
| PCI DSS | v3.2.1 | PCI.DSS.3.4 | No aplicable al caso de uso |
Controles Personalizados para Cumplimiento Médico:
| Control | Descripción | Severidad | Tipo | Estado |
|---|---|---|---|---|
| Medical Data Encryption at Rest | Verificar que todos los datos médicos están cifrados con KMS CMK | CRÍTICA | Healthcare Standards | PASSED |
| Clinical API Rate Limiting | Asegurar que API Gateway tiene rate limiting configurado | ALTA | AWS Security Best Practices | PASSED |
Proceso de Configuración:
- Habilitar estándares - El equipo de seguridad habilita cada estándar mediante suscripción batch
- Aplicar excepciones - Los controles no aplicables se deshabilitan con justificación documentada
- Crear controles personalizados - Se definen controles específicos para requisitos médicos y se importan en Security Hub
- Validación continua - Security Hub evalúa continuamente el cumplimiento de todos los controles
Gestión de Vulnerabilidades Cloud
Scanning Continuo de Infraestructura
Escaneo de Contenedores (ECR):
- Escaneo al push: Habilitado
- Frecuencia de escaneo: Diaria
Umbrales de Severidad:
| Severidad | Acción |
|---|---|
| CRÍTICA | Bloquear despliegue |
| ALTA | Alerta y revisión obligatoria |
| MEDIA | Seguimiento para remediación |
| BAJA | Revisión mensual |
Escaneo en Tiempo de Ejecución:
- Herramienta: AWS Inspector
- Frecuencia: Continua
- Cobertura: Todos los contenedores de producción
Escaneo de Infraestructura (AWS Inspector):
| Plantilla de Evaluación | Frecuencia | Alcance |
|---|---|---|
| Network Reachability | Semanal | Todas las instancias EC2 y contenedores |
| Security Best Practices | Semanal | Todas las instancias EC2 y contenedores |
| CVE Scanning | Semanal | Todas las instancias EC2 y contenedores |
| CIS Benchmarks | Semanal | Todas las instancias EC2 y contenedores |
Herramientas de Terceros:
| Herramienta | Integración | Frecuencia |
|---|---|---|
| Qualys VMDR | AWS Connector | Diaria |
| Tenable.io | API | Continua |
Gestión de Parches:
Parcheado Automatizado:
- Parches de SO:
- Herramienta: AWS Systems Manager Patch Manager
- Ventana de mantenimiento: Domingos 02:00-06:00 UTC
- Retraso de aprobación: 7 días para producción
- Parches de Aplicaciones:
- Proceso: Pipeline CI/CD con puertas de seguridad
- Testing: Regresión automatizada + pruebas de seguridad
Parches de Emergencia:
- Vulnerabilidades críticas:
- SLA: 24 horas
- Aprobación: Responsable de Seguridad o delegado
- Testing: Validación de seguridad expedita
Gestión de Secretos y Credenciales
AWS Secrets Manager Integration
El equipo de desarrollo crea secretos para aplicaciones médicas siguiendo un proceso estandarizado:
Política de Recursos Restrictiva:
- Efecto: Denegar acceso por defecto
- Condiciones de acceso:
- Solo principals con tag
Environment=Production - Solo principals con tag
Authorized=True
- Solo principals con tag
Proceso de Creación de Secretos:
-
Crear secreto con las siguientes características:
- Descripción: "Medical application secret - regulated data"
- Cifrado: KMS CMK específica para datos médicos (key/medical-cmk)
- Valor: JSON estructurado con las credenciales
-
Aplicar etiquetas obligatorias:
| Etiqueta | Valor | Propósito |
|---|---|---|
| Compliance | MDR | Identificar requisito regulatorio |
| DataClassification | Confidential | Clasificación de datos |
| Rotation | Enabled | Estado de rotación |
- Configurar rotación automática:
- Función Lambda: secret-rotation
- Frecuencia: Cada 90 días
- Proceso automático sin intervención manual
Responsabilidades:
- Equipo de desarrollo: Solicita creación de secretos según necesidad
- Equipo de seguridad: Valida políticas y aprueba creación
- Sistema automatizado: Gestiona la rotación periódica
Referencias Cruzadas y Trazabilidad
Mapeo de Controles Cloud a Requisitos
| Control ENS | Servicio AWS | Configuración | Evidencia |
|---|---|---|---|
| mp.com.1 | CloudFront + WAF | TLS 1.3, WAF rules | CloudWatch Logs |
| mp.com.2 | VPC + Security Groups | Network segmentation | VPC Flow Logs |
| mp.cryp.1 | KMS | CMK con rotación anual | CloudTrail |
| mp.info.3 | S3 + Encryption | SSE-KMS | S3 Access Logs |
| op.acc.1 | IAM + API Gateway | MFA obligatorio (admin) | CloudTrail |
| op.exp.8 | CloudWatch Logs | 7 años retención | Log Groups |
| op.mon.1 | GuardDuty | Threat detection activo | Findings |
| op.cont.2 | Multi-region DR | RTO < 4h, RPO < 15m | DR tests |
Integración con Sistema de Gestión de Riesgos
Riesgos Específicos de Cloud:
| ID Riesgo | Descripción | Controles Aplicados | Referencias ENS |
|---|---|---|---|
| R-CLD-001 | Caída de servicios AWS afectando disponibilidad | • Despliegue multi-región • Procedimientos DR | OP.CONT.2, OP.CONT.4 |
| R-CLD-002 | Brecha de datos por bucket S3 mal configurado | • S3 Block Public Access • Políticas de bucket | MP.INFO.3, OP.ACC.2 |
| R-CLD-003 | Acceso no autorizado a datos médicos | • Políticas IAM • MFA obligatorio • Logging CloudTrail | OP.ACC.1, OP.ACC.5, OP.EXP.8 |
Referencias al Modelo de Amenazas:
- T-024-006-CLD-001: Compromiso de servicios cloud
- T-024-006-CLD-002: Amenaza interna en entorno cloud
- T-024-006-CLD-003: Ataque a la cadena de suministro vía servicios cloud
- T-024-006-CLD-004: Violaciones de residencia de datos
Procedimientos Operativos Cloud
Gestión de Cambios en Infraestructura Cloud
Infraestructura como Código (IaC):
Control de Versiones:
- Repositorio: [repositorio de infraestructura de la organización]
- Estrategia de branching: GitFlow
- Protección: Rama main protegida, revisiones obligatorias
Flujo de Trabajo con Terraform:
| Fase | Actividades | Responsable |
|---|---|---|
| 1. Plan | • terraform plan • Security scanning (tfsec, checkov) • Estimación de costes • Verificación de cumplimiento | Equipo de infraestructura |
| 2. Review | • Revisión por pares obligatoria • Aprobación del equipo de seguridad (recursos críticos) • Change Advisory Board (producción) | Pares + Seguridad + CAB |
| 3. Apply | • terraform apply con aprobación • Testing automatizado • Validación de monitorización | Equipo de infraestructura |
| 4. Validation | • Health checks • Validación de seguridad • Plan de rollback preparado | SRE + Seguridad |
Ventanas de Cambio:
| Entorno | Ventana Regular | Ventana de Emergencia |
|---|---|---|
| Production | Domingos 02:00-06:00 UTC | Con aprobación del Responsable de Seguridad |
| Staging | Diaria 22:00-02:00 UTC | No requerida |
| Development | Sin restricciones | No aplicable |
Runbooks de Operación Cloud
Runbook: Escalado de Emergencia
Triggers de Activación:
- CPU > 90% durante 5 minutos
- Response Time > 2s durante 5 minutos
Factor de Escalado: 2x (configurable)
Procedimiento de Ejecución:
- Verificar estado actual
- Quien: Sistema automatizado / Ingeniero SRE
- Qué: Obtener el estado actual del servicio ECS incluyendo número de tareas deseadas, en ejecución y pendientes
- Resultado: Estado actual documentado
- Escalar inmediatamente
- Quien: Sistema automatizado
- Qué: Multiplicar el número de tareas deseadas por el factor de escalado
- Ejemplo: Si hay 4 tareas, escalar a 8 tareas
- Resultado: Nuevas instancias del servicio iniciándose
- Ajustar política de auto-scaling
- Quien: Sistema automatizado
- Qué: Actualizar los límites de la política de auto-scaling para reflejar la nueva capacidad
- Resultado: Auto-scaling configurado para el nuevo nivel
- Notificar stakeholders
- Quien: Sistema automatizado
- Qué: Enviar notificación con detalles del escalado (servicio, factor, timestamp)
- Destinatarios: Equipo SRE, equipo de desarrollo, management
- Resultado: Equipo informado del escalado
- Activar monitorización mejorada
- Quien: Sistema automatizado
- Qué: Crear dashboards temporales con métricas detalladas del servicio
- Duración: Hasta que el incidente se resuelva
- Resultado: Visibilidad mejorada durante el incidente
Formación y Concienciación Cloud Security
Programa de Formación
Formación de Onboarding:
| Rol | Módulos de Formación | Duración |
|---|---|---|
| Nuevos Desarrolladores | • AWS Security Fundamentals • Shared Responsibility Model • IAM Best Practices • Secure Coding for Cloud | 16 horas |
| Nuevas Operaciones | • AWS Well-Architected Framework • Security Monitoring and Incident Response • Compliance and Audit • Cost Optimization | 24 horas |
Educación Continua:
Briefing Mensual de Seguridad:
- Últimas amenazas y vulnerabilidades
- Nuevas características de seguridad de AWS
- Lecciones aprendidas de incidentes
- Actualizaciones de cumplimiento
Talleres Trimestrales:
- Laboratorios prácticos de seguridad
- Simulaciones de respuesta a incidentes
- Revisiones de arquitectura
- Formación en herramientas
Certificaciones:
| Categoría | Certificación | Audiencia |
|---|---|---|
| Obligatorias | AWS Certified Cloud Practitioner | Todo el personal |
| Obligatorias | AWS Certified Security - Specialty | Equipo de seguridad |
| Recomendadas | AWS Certified Solutions Architect | Arquitectos y desarrolladores senior |
| Recomendadas | AWS Certified DevOps Engineer | Equipo SRE y DevOps |
| Recomendadas | AWS Certified Database Specialty | Administradores de bases de datos |
Métricas y KPIs de Seguridad Cloud
Dashboard de Seguridad Cloud
| Métrica | Target | Current | Trend | Status |
|---|---|---|---|---|
| Compliance Score | > 95% | 97.2% | ↑ | ✅ |
| Unencrypted Resources | 0 | 0 | → | ✅ |
| Public S3 Buckets | 0 | 0 | → | ✅ |
| MFA Coverage | 100% | 100% | → | ✅ |
| Patch Compliance | > 98% | 99.1% | ↑ | ✅ |
| Security Findings (High) | < 5 | 3 | ↓ | ✅ |
| MTTR (Incidents) | < 4h | 2.3h | ↓ | ✅ |
| Failed Auth Attempts | < 100/day | 67/day | ↓ | ✅ |
| API Rate Limit Hits | < 50/day | 23/day | ↓ | ✅ |
| Cost Optimization | > 20% | 23% | ↑ | ✅ |
Anexos
Anexo A: Checklist de Seguridad Cloud
- Todos los recursos etiquetados correctamente
- MFA habilitado para todos los usuarios
- CloudTrail activo en todas las regiones
- S3 Block Public Access habilitado
- VPC Flow Logs activos
- GuardDuty habilitado
- Security Hub configurado
- Config Rules activas
- Secrets rotados < 90 días
- Backups verificados < 30 días
- DR test < 90 días
- Pentest < 12 meses
Anexo B: Contactos de Emergencia AWS
Soporte AWS:
- Tier: Enterprise
- Teléfono: +1-800-xxx-xxxx
- Prioridad: Business Critical
Seguridad AWS:
- Reporte de abuso: abuse@amazonaws.com
- Incidentes de seguridad: Vía Support Console
Escalado Interno:
| Nivel | Contacto | |
|---|---|---|
| L1 | SRE On-call | [email interno] |
| L2 | Equipo de Seguridad | [email interno] |
| L3 | Responsable de Seguridad | [email interno] |
| Ejecutivo | Responsable del Sistema | [email interno] |
Signature meaning
The signatures for the approval process of this document can be found in the verified commits at the repository for the QMS. As a reference, the team members who are expected to participate in this document and their roles in the approval process, as defined in Annex I Responsibility Matrix of the GP-001, are:
- Author: Team members involved
- Reviewer: JD-003 Design & Development Manager, JD-004 Quality Manager & PRRC
- Approver: JD-001 General Manager