R-TF-012-009 Validation and testing of machine learning models_2023_001
Description of the methodologies
The device includes a variety of different machine learning models, each one requiring specific metrics and methodologies to test their performance. The models can be categorized into three main groups:
- Image recognition models
- Object detection models
- Semantic segmentation models
Each model operates in different scenarios, meaning that the output of one model does not influence the output of the others. For that reason, it is not required to test the impact of any improved model against the others.
Common practices
These are some common practices that are followed during the development of every machine learning model of the device:
- Supervised learning: All the models are trained on labelled datasets, which means that every data sample has both input features (like images) and corresponding target labels.
- Transfer Learning: Our models leverage pre-trained weights from classification tasks like ImageNet, capitalizing on previously learned features that are highly relevant to our objectives. Given ImageNet's diverse array of categories encompassing people, skin tones, and real-life objects, numerous features directly align with our datasets, enriching our model's ability to extract meaningful representations.
- Data splitting: Every dataset is split into training, validation and test subsets. The training set is used to fit a model, and the validation set is used to evaluate the performance of the model after every training iteration. Lastly, the test set is used once training is finished to evaluate the model on entirely independent data, which offers an unbiased assessment of performance. Data is always split in a manner that ensures that training, validation and test sets contain a representative sample of images that the models are expected to encounter in real-world scenarios.
- Subject stratification: In some datasets, there are subject-related metadata that can be used to make the splits without the risk of data leakage. In cases when such metadata are not available, it is possible to manually group the data by subject and then make the splits.
- Dataset stratification: In addition to subject stratification, separating by dataset ensures that similar images, influenced by specific image conditions or artifacts present in certain hospitals or sources, do not overlap between training and testing phases.
- Fixed test set: The test set remains fixed unlike the training and validation sets. Therefore, models are consistently evaluated on the same robust data, facilitating fair comparisons and benchmarking against a standardized dataset.
- Data Augmentation: We expand our training dataset by employing various transformations like rotation, flipping, or cropping, thereby amplifying the diversity of training samples and bolstering the resilience of our model. Moreover, we tailor our augmentation techniques to the specific domain, implementing manual crops around regions of interest and adjusting lighting conditions to further enrich the dataset and enhance model performance.
- Model Evaluation Metrics: Selecting appropriate evaluation metrics based on the problem domain (e.g., accuracy, precision, recall, F1-score for classification) to effectively assess model performance. The metrics are defined in next sections.
When working with small subsets of images, instead of using the standard train/validation/test approach, the data is split into training and validation sets. This ensures a larger validation set that provides more reliable metrics than using a test set with very few samples. In this setting, the validation set is used for both evaluating hyperparameter choices and model performance.
Image recognition
Image recognition models are used to categorize input images into N classes. The output of an image recognition model is a discrete probability distribution of N values. In other words, the model predicts how likely it is that each of the N classes is represented in the input image.
To assess the effectiveness of our image recognition models, we employ a range of metrics tailored to specific use cases, including:
- Accuracy: ratio of correct predictions. A prediction is usually considered correct when the class with the highest predicted probability matches the ground truth class. However, this usually limits the power of the analysis, so other variants must be explored. To overcome this limitation, top-K accuracy is the most common metric used to evaluate performance. For this metric, the prediction is correct if the correct class is within the top K classes with the highest predicted probability. Top-3 and top-5 are the most usual applications of top-K accuracy.
- Balanced accuracy (BAC): when working with highly imbalanced datasets, the performance of the underrepresented classes can't be properly understood with the accuracy metric. To overcome this, balanced accuracy averages per-class accuracies according to the frequencies (i.e. the number of samples) of each class.
- Sensitivity and specificity: used in binary classification. Sensitivity is the ratio of true positives to the total positives (also called the true positive rate), whereas specificity is the ratio of true negatives to the total negatives (also called the true negative rate).
- Precision and recall: Precision measures the fraction of correct positive predictions out of all positive predictions, while recall measures the fraction of correct positive predictions out of all actual positive instances. These metrics are particularly useful when dealing with imbalanced datasets, where the number of positive and negative instances is significantly different.
- Area under the ROC Curve (AUC): commonly used metric to evaluate the performance of binary classification models. This is particularly useful for binary indicators, such as the malignancy indicator. The ROC (Receiver Operating Characteristic) curve is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied.
- Relative Mean Absolute Error (RMAE): serves as a metric for assessing the performance of regression models. It shares similarities with the Mean Absolute Error (MAE), yet offers a relative evaluation of error by presenting absolute errors as a percentage of the actual values. This metric finds its utility in scenarios where the problem is akin to a classification task with discrete intensity values, but performance evaluation necessitates measurement in terms of these intensity values, hence adopting a regression approach.
- Linear correlation: commonly known as the Pearson correlation coefficient, is a statistical metric that gauges the strength and direction of the linear relationship between two variables. Similar to RMAE, it finds utility in scenarios prioritizing regression performance over precise ordinal categorization.
These metrics are computed at different levels:
- By considering the entire validation or test set, we obtain the overall metrics, that help summarize overall performance.
- When the dataset has been made from several sources, we compute source-level metrics, which summarize performance on each source. This stratification helps analyze which data is generating the best results and detect any possible bias (i.e. a model does great on one subset but poorly on another).
- For the specific case of image-based recognition of ICD categories, sensitivity and specificity are computed for every class. In other words, an N-class classification problem is evaluated as an N-binary classification problem. In order to conduct more powerful analyses, top-3 and top-5 sensitivity and specificity have been developed and computed.
Other overall metrics are:
- Confusion matrix: It provides a tabular representation of the network's predictions versus the ground truth labels. It helps visualize the number of true positives, true negatives, false positives, and false negatives, allowing for a detailed analysis of the model's performance.
- F1 Score: The F1 score combines precision and recall into a single metric. It is the harmonic mean of precision and recall, providing a balanced measure of a model's performance.
Additionally, we also make use of image similarity search techniques to assess performance in a more qualitative manner. This method consists of comparing a test image to the entire training set to find the most similar training images. This gives us a more intuitive understanding of which visual cues might be used by the models to make predictions. Similarity search requires an embedding database, which contains the image embeddings of the training set. Whenever we want to run a similarity search query for a new test image, we obtain its corresponding the embeddings and compare them to the training database using a similarity metric (either Euclidean distance or cosine similarity).
The following image is an example of a similarity search: given a test query image (left), the top-10 most similar images are retrieved from the embedding database.

An image embedding in computer vision is a compact numerical representation of an image, capturing its essential features in a reduced space of fewer dimensions than the original input. In a typical deep learning model architecture, the image embedding is the output of the model's bottleneck, and it is later processed by one or more fully-connected layers to produce the final output for a given task (classification, regression, etc.).
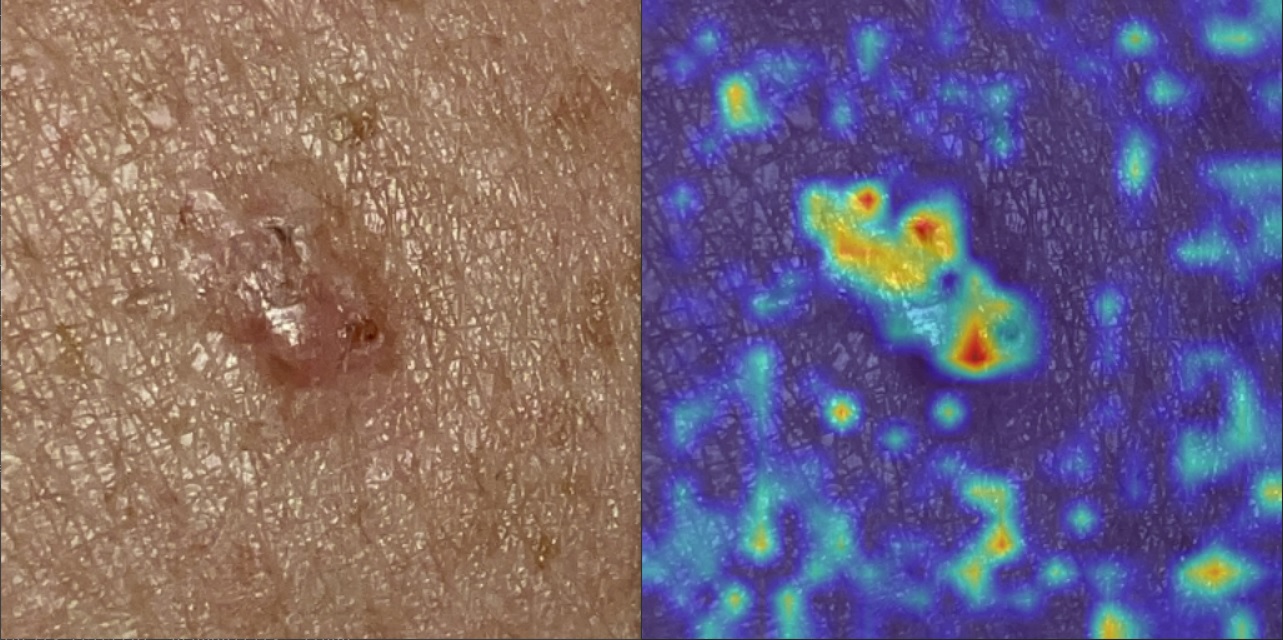
Another explainable AI (also known as XAI) method we use is gradient-weighted class activation maps (GradCAM). GradCAM is a popular visualization technique useful for understanding how the model has been driven to make a classification decision. It is class-specific, which provides us with separate visualizations for each category. This lets us explore activations at inference time. GradCAM, together with similarity search, helps uncover unexpected biases and provides directions in which improve training.
The following example shows an image of a basal cell carcinoma (BCC) and the corresponding activation map for the 2C32 Basal cell carcinoma of skin ICD-11 category:
Object detection
Object detection models are trained to detect instances of semantic objects of certain classes. The output of an object detection model is a list of objects, each of them consisting of:
- A bounding box, described by its (X, Y) location in the image and its width and height in pixels.
- A class prediction that describes what kind of object is inside the bounding box. This is often accompanied by a confidence score, indicating how confident the model is in its prediction.
In order to train an object detection model on a given dataset, the annotators must label the images in the same manner (i.e. annotating the bounding boxes). The labels from all annotators are processed to obtain the consensus, which is used to fit the model.
The metrics to evaluate object detection models are:
- Precision and recall: in the context of object detection, precision is calculated as the ratio of true positive detections to the total number of detections, both correct and incorrect, whereas recall is calculated as the ratio of true positive detections to the total number of actual positive objects in the image.
- Mean average precision (mAP): commonly used evaluation metric in object detection, which calculates the average precision of a model at various recall thresholds, and then computes the mean of these values. It provides a single score to assess the performance of a model across different levels of recall, with higher mAP indicating better accuracy.
- Intersection over Union (IoU): measures the overlap between predicted bounding boxes and the ground truth, indicating how well the model's predictions align with the actual objects in the image.
- Mean Absolute Error (MAE): widely used metric for assessing the performance of regression models. It quantifies the average absolute differences between the model's predicted values and the actual values. In the context of object detection, where the model outputs multiple bounding boxes often used for counting rather than just spatial localization, regression metrics like MAE provide a suitable means to gauge performance, aligning closely with the practical application of the model.
Semantic segmentation
Semantic segmentation models perform classification at the pixel level. The output of a segmentation model is an image of identical dimensions to the input image, where each pixel is assigned a class label. For each class, the areas of the images that have been classified as such are called segmentation masks, which are compared to the ground truth masks labelled by the annotators. When developing new datasets, the data is always annotated by at least 3 observers, and the consensus of all the observers is used as ground truth.
To evaluate semantic segmentation models, the metrics used are:
- Intersection over Union (IoU): measures the overlap between predicted masks and the ground truth masks, indicating how well the model's predictions align with the actual objects in the image.
- Precision and recall: in the context of semantic segmentation, precision is the proportion of pixels that were correctly classified as belonging to a particular class (true positives) out of all the pixels predicted as belonging to that class. Recall is the proportion of pixels that were correctly classified as belonging to a particular class (true positives) out of all the pixels that actually belong to that class (true positives + false negatives).
- F1 score: metric commonly used to evaluate the performance of classification models. It is the harmonic mean of precision and recall, providing a balanced assessment of a model's ability to correctly identify both positive and negative instances. In the context of segmentation models, the F1 score can be adapted to assess performance by treating the segmentation task as a binary classification problem. Each pixel is classified as either belonging to the visual sign of interest or not.
- Area under the ROC Curve (AUC): just as in image recognition models, AUC can also be applied in segmentation tasks, where models classify at the pixel level rather than the image level. AUC serves as a valuable metric for evaluating the performance of such models in distinguishing visual signs from the background or other categories.
Record signature meaning
- Author: JD-009
- Reviewer: JD-003
- Approval: JD-005